User profiles extraction from dialogue with Transformer-based models for conditional generation
Research goal: To develop a model extracting user attributes from dialogue and persona.
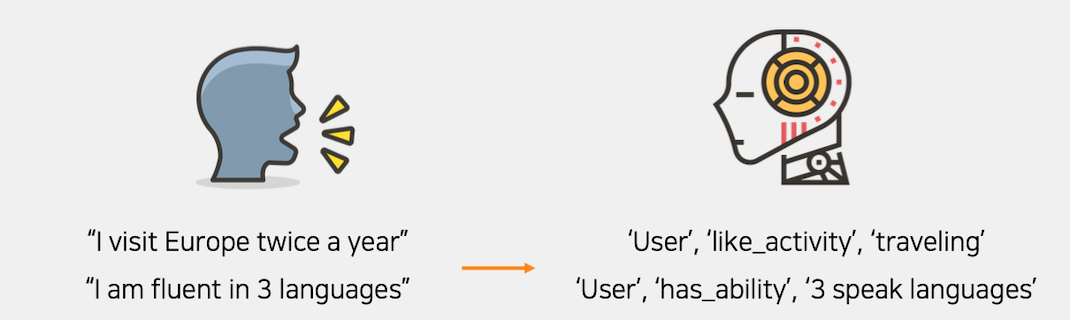
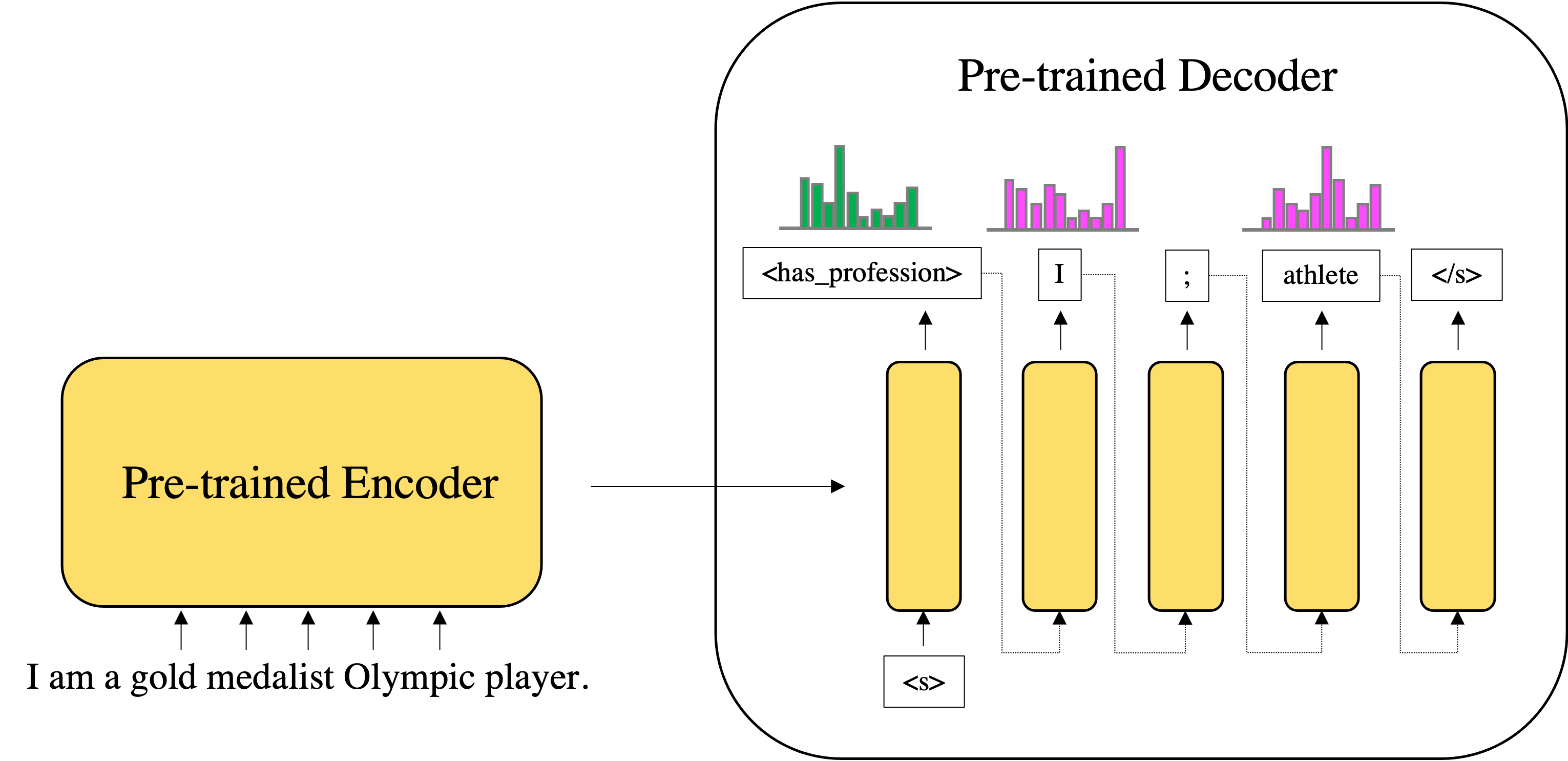
Fine-tuned Transformer-based model for a conditional generation to extract users’ profiles from dialogue history and persona sentences.
Measured the influence of predicates in autoregressive decoder by changing the order of target triplets.
Analyzed the model’s performance depending on the semantic groups of predicates classifed based on FrameNet.
Results and Insights
Our suggested model outperforms other baseline models, with 0.56 F1-score and 0.57 BLEU-1 score.
A model trained by generating predicates first or following the grammatical order ‘subject-predicate-object’ shows better performance than other models.
Lack of commonsense reasoning: The model could not extract that ‘I have father’ from the sentence ‘My father likes watching baseball’, while successfully extracted the triplet ‘my father, has_hobby, watching baseball’.
Biomedical predicate classification using SemMedDB
Research goal: To build relation extraction model between unseen biomedical entities.
Opened dataset, BioPREP, with 165,799 sentences, each labeled with 28 predicates.
Fine-tuned BioBERT for predicate classification.
Analyzed the difference of model’s performance depending on seven semantic groups defined by FrameNet.
Results and Insights
Lack of deeper understanding: The model still struggled in capturing relations when the input sentence is quite long or contains complex local features occurring a subtle difference in meaning. For instance, our model extracts the relation name as ‘Occurs in’ from the input sentence ‘The occurrence of chromosome PHENOTYPE in PHENOTYPE may be associated with incomplete manifestation of the syndrome’, while the ground truth for relation name is ‘Process of’.
Though our pre-trained model showed the best performance, I think that our model does not fully understand given biomedical sentences semantically in some cases, only capturing the superficial correlation to infer target labels.
WR / ERA / AVG Prediction model for Korean Baseball Teams
Project goal: To build a system to predict Win Rate, Batting Average, and Earned Run Average for Korean baseball teams.
Two-stage architecture: Predict ERA and AVG first with LSTM. 2) Infer WR using ‘Predicted ERA’ and ‘Predicted AVG’ as newly added features, with LightGBM.
Made embedding vectors by using scaled raw records and a multiple of derived features.
26 consequential embedded vectors were used as the inputs of LSTM. Pooled the last hidden state of the LSTM layer to predict WR, ERA and AVG.
Scaled moving average of 26 consequential game features were used as input in LightGBM.
Best performance across 1,500 teams participated.
Achievement: Grand Prize (Minister’s Award) at Big Contest 2020, National Information Society Agency, Korea
Fake News Detection Challenge
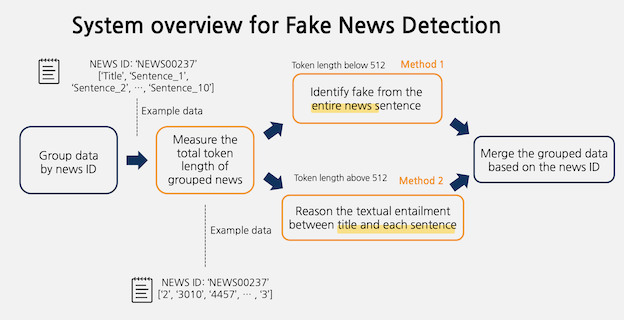
Project goal: To develop a model that filters fake news having no relation with main news contents.
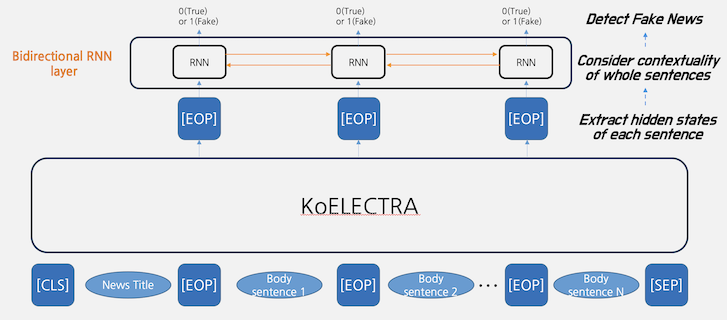
Designed two-stage sequence classification algorithm with bidirectional RNN and ELECTRA.
Analyzed the relationship between news headline and each body sentences.
Improved time complexity by dynamic padding and uniform length batching.
1st on public leaderboard, 5th on private leaderboard across 1,000 teams participated.
Achievement: Winning a prize at NLP Competition, NH Investment & Securities, Korea